HumanSplat: Closing the Loop Between Human Mesh Recovery and Gaussian Splatting Avatars
Abstract
Accurately recovering human pose and appearance from video is an essential component of scene reconstruction, with applications to motion capture, motion prediction, virtual reality, and digital twinning. Despite significant interest in building realistic human avatars from video, this paper demonstrates that existing methods do not accurately recover the 3D geometry of humans. ViT-based approaches are not consistently reliable and can overfit to 2D views, while NeRF- and Gaussian Splatting–based avatars treat pose and appearance separately, limiting rendering generalization to new poses. To resolve these shortcomings, this paper proposes HumanSplat, a joint optimization framework that refines 3D human poses while simultaneously learning a high-fidelity avatar for novel-view and novel-pose synthesis. Our key insight is to close the loop between geometric pose estimation and differentiable rendering. Unlike prior human avatar methods that rely on accurate human pose obtained through motion capture systems or offline refinement, which are impractical in in-the-wild scenarios, our approach uses only human mesh estimates from a state-of-the-art human pose estimator to better reflect real-world conditions. Therefore, instead of using the human pose only as a deformation prior, HumanSplat backpropagates photometric, segmentation, and depth losses through a differentiable renderer to the pose parameters and global position. This coupling refines the global 3D pose over time, improving accuracy and alignment while producing better renderings from novel views. Experiments show consistent improvements over pose recovery baselines that omit image-level refinement and avatar baselines that decouple pose estimation from avatar reconstruction.

Method Overview
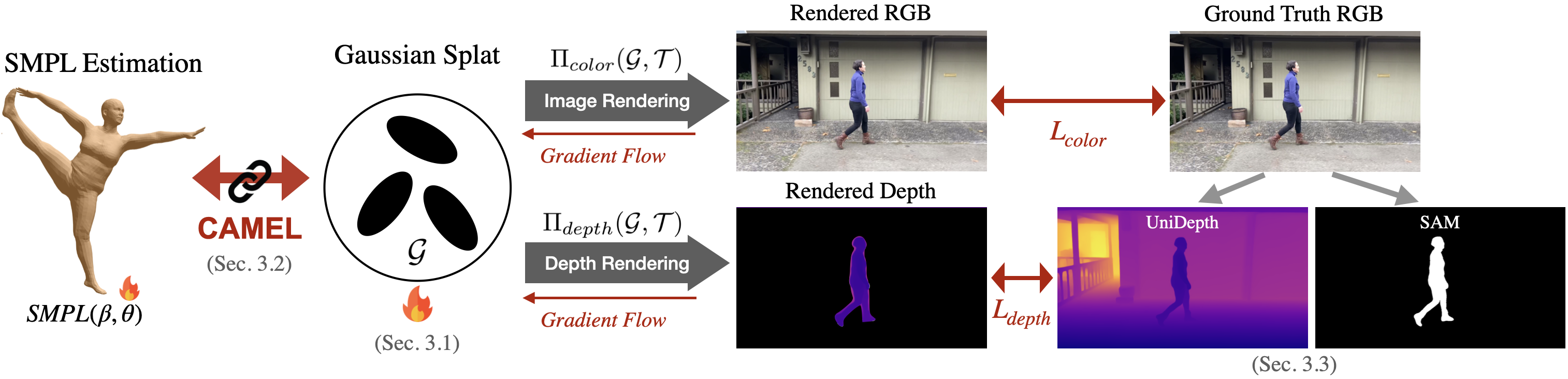
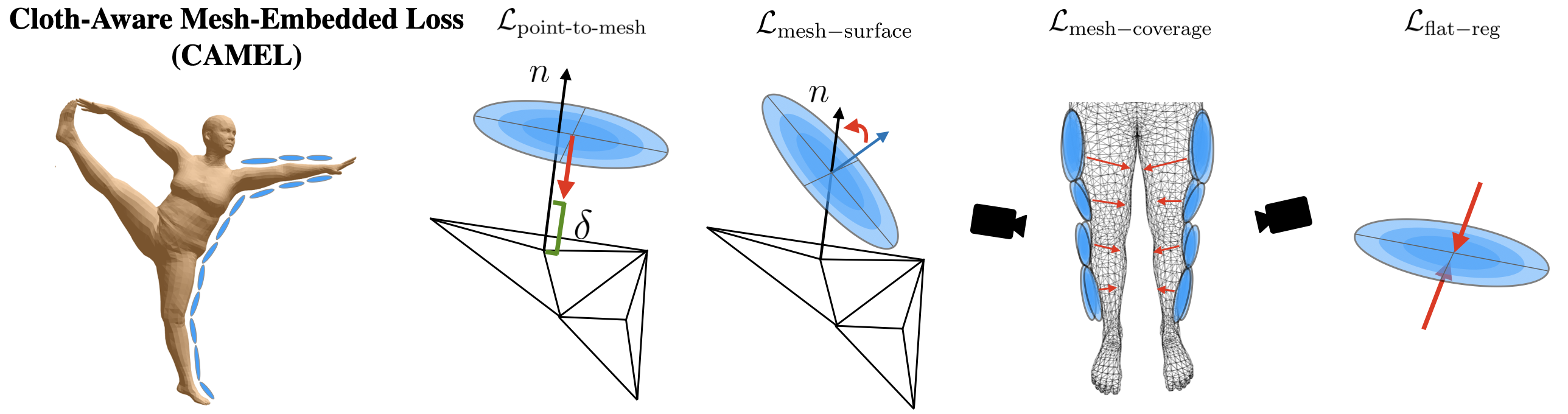
BibTeX
@article{zongkung2025humansplat,
title={HumanSplat: Closing the Loop Between Human Mesh Recovery and Gaussian Splatting Avatars},
author={Zong, Yeheng* and Kung, Pou-Chun* and Pan, Yike and Isaacson, Seth and Chen, Yizhou and Vasudevan, Ram and Skinner, Katherine A.},
journal={In Submission 2025},
year={2025},
url={https://scottyehengz.github.io/HumanSplat/}
}